1. 캐글(Kaggle)
- 구글에서 운영하는 전세계 AI 개발자, 데이터 사이언티스트들이 데이터를 분석하고 토론할 수 있는 자료 등을 제공
- 데이터 분석 및 머신러닝, 딥러닝 대회를 개최
- 데이터셋, 파이썬 자료, R 자료 등을 제공
- [캐글 공식 사이트]: https://kaggle.com
2. 데이콘(Dacon)
- 국내 최초 AI 해커톤 플랫폼
- 전문 인력 채용과 학습을 할 수 있는 여러가지 AI 자료 등을 제공
- [데이콘]: https://dacon.io/
3. AI 허브
- 한국지능정보사회진흥원이 운영하는 AI 통합 플랫폼
- AI 기술 및 제품 서비스 개발에 필요한 AI 인프라를 제공
- AI허브(https://www.aihub.or.kr/)
#4. 타이타닉 데이터
https://bit.ly/fc-ml-titanic
import pandas as pd
df = pd.read_csv('https://bit.ly/fc-ml-titanic')
df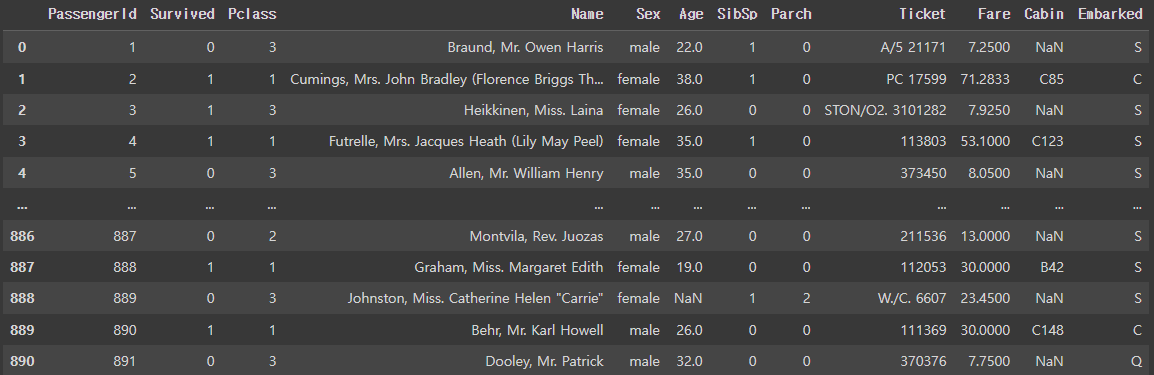
- PassengerId: 승객아이디
- Survived: 생존여부 (0: 사망, 1:생존)
- Pclass : 좌석 등급
- Name : 이름
- Sex : 성별
- Age: 나이
- SibSp : 형제,자매,배우자 수
- Parch : 부모, 자식 수
- Ticket : 티켓 번호
- Fare : 요금
- Cabin : 선실
- Embarked : 탑승 항구
- 데이터 정제 작업을 뜻함
- 필요없는 데이터를 삭제하고, null이 있는 행을 처리하고,
정규화/표준화 등의 많은 작업들을 포함 - 머신러닝, 딥러닝 실무에서 전처리가 차지하는 중요도는 50% 이상이라고 봄
- 5. 데이터 전처리
5-1. 독립변수와 종속변수 나누기
# feature = ['Pclass', 'Sex', 'Age', 'Fare'] # 독립변수
# label = ['Survived'] # 종속변수
columns = ['Pclass','Sex','Age','Fare','Survived']
df[columns].head()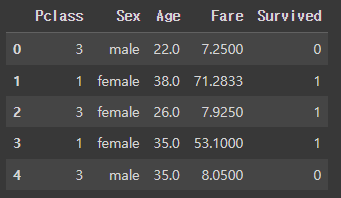
df['Survived'].value_counts()
출력:
Survived
0 549
1 342
Name: count, dtype: int645-2. 결측치 처리
df.info()
출력:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
df.isnull().mean()
출력:
PassengerId 0.000000
Survived 0.000000
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 0.198653
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.000000
Cabin 0.771044
Embarked 0.002245
dtype: float64df['Age'] = df['Age'].fillna(df['Age'].mean()) # Age 컬럼의 결측값을 평균값 으로 대입
df['Age']
출력:
0 22.000000
1 38.000000
2 26.000000
3 35.000000
4 35.000000
...
886 27.000000
887 19.000000
888 29.699118
889 26.000000
890 32.000000
Name: Age, Length: 891, dtype: float645-3. 라벨 인코딩(Label Encoding)
- 문자(Categorical) 를 수치(Numerical)로 변환
df['Sex'].value_counts()
출력:
Sex
male 577
female 314
Name: count, dtype: int64# 남자는 1, 여자는 0 으로 변환하는 함수
def convert_sex(data):
if data == 'male':
return 1
elif data == 'female':
return 0df['Sex'] = df['Sex'].apply(convert_sex)
df.head()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['Embarked'].value_counts()
출력:
Embarked
S 644
C 168
Q 77
Name: count, dtype: int64embarked = le.fit_transform(df['Embarked'])
embarked # null : 3
출력:
array([2, 0, 2, 2, 2, 1, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 1, 2, 2, 0, 2, 2,
1, 2, 2, 2, 0, 2, 1, 2, 0, 0, 1, 2, 0, 2, 0, 2, 2, 0, 2, 2, 0, 0,
1, 2, 1, 1, 0, 2, 2, 2, 0, 2, 0, 2, 2, 0, 2, 2, 0, 3, 2, 2, 0, 0,
2, 2, 2, 2, 2, 2, 2, 0, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2,
...
le.classes_ # array(['C','Q','S',nan])
출력:
array(['C', 'Q', 'S', nan], dtype=object)5-4. 원 핫 인코딩(One Hot Encoding)
- 독립적인 데이터는 별도의 컬럼으로 분리하고 각각 컬럼에 해당 값에만 1, 나머지는 0 의 값을 갖게 하는 방법
df['Embarked_num'] = LabelEncoder().fit_transform(df['Embarked'])
df.head()
pd.get_dummies(df['Embarked_num'])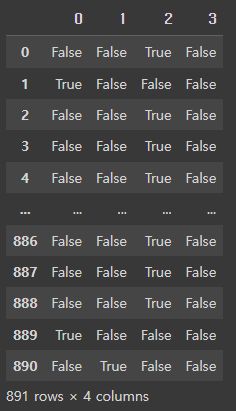
df = pd.get_dummies(df, columns=['Embarked'])
df.head()
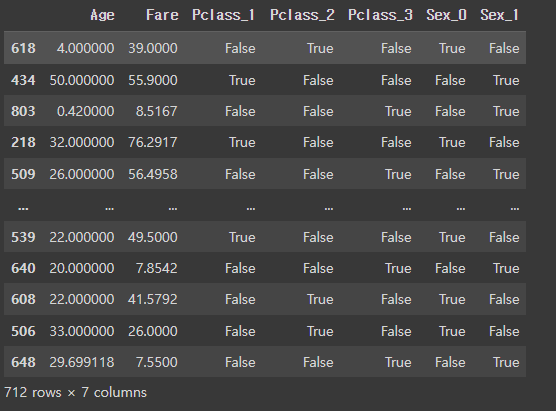
df = df[columns]
df
df = pd.get_dummies(df, columns=['Pclass','Sex'])
df.head()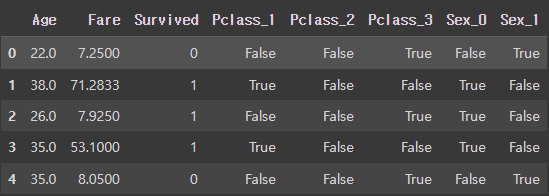
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('Survived', axis=1),df['Survived'], test_size=0.2, random_state=2024)
X_train.shape, X_test.shape
출력: ((712, 7), (179, 7))
y_train.shape, y_test.shape
출력: ((712,), (179,))X_train