1. 파이토치(Pytorch)¶
- Tensorflow와 함께 머신러닝, 딥러닝에서 가장 널리 사용되는 프레임워크
- 초기에는 Torch라는 이름으로 Lua언어 기반으로 만들어 졌으나, 파이썬 기반으로 변경한것이 Pytorch
- 뉴욕대학교와 페이스북(메타)이 공동으로 개발하였고, 현재 가장 대중적인 머신러닝, 딥러닝 프레임워크
In [1]:
import torch
print(torch.__version__)
2.3.0+cu121
In [2]:
var1 = torch.tensor([1])
print(var1)
tensor([1])
In [3]:
var1
Out[3]:
tensor([1])
In [4]:
type(var1)
Out[4]:
torch.Tensor
In [5]:
var2 = torch.tensor([10.5])
var2
Out[5]:
tensor([10.5000])
In [6]:
# 두 스칼라의 사칙 연산
print(var1 + var2)
print(var1 - var2)
print(var1 * var2)
print(var1 / var2)
tensor([11.5000]) tensor([-9.5000]) tensor([10.5000]) tensor([0.0952])
1-2. 벡터(Vector)¶
- 상수가 두 개 이상 나열된 경우
In [7]:
vec1 = torch.tensor([1, 2, 3])
vec1
Out[7]:
tensor([1, 2, 3])
In [8]:
vec2 = torch.tensor([1.5, 2.4, 3.3])
vec2
Out[8]:
tensor([1.5000, 2.4000, 3.3000])
In [9]:
# 두 벡터의 사칙연선
print(vec1 + vec2)
print(vec1 - vec2)
print(vec1 * vec2)
print(vec1 / vec2)
tensor([2.5000, 4.4000, 6.3000]) tensor([-0.5000, -0.4000, -0.3000]) tensor([1.5000, 4.8000, 9.9000]) tensor([0.6667, 0.8333, 0.9091])
In [10]:
vec3 = torch.tensor([5, 10, 15, 20])
vec3
Out[10]:
tensor([ 5, 10, 15, 20])
In [11]:
# vec1 + vec3 # RuntimeError: The size of tensor a (3) must match the size of tensor b (4) at non-singleton dimension 0
1-3. 행렬(Matrix)¶
- 2개 이상의 벡터값을 가지고 만들어진 값으로 행과 열의 개념을 가진 데이터의 나열
In [12]:
mat1 = torch.tensor([[1, 2], [3, 4]])
print(mat1)
tensor([[1, 2],
[3, 4]])
In [13]:
mat2 = torch.tensor([[7, 8], [9, 10]])
print(mat2)
tensor([[ 7, 8],
[ 9, 10]])
In [14]:
# 두 행렬의 사칙 연산
print(mat1 + mat2)
print(mat1 - mat2)
print(mat1 * mat2)
print(mat1 / mat2)
tensor([[ 8, 10],
[12, 14]])
tensor([[-6, -6],
[-6, -6]])
tensor([[ 7, 16],
[27, 40]])
tensor([[0.1429, 0.2500],
[0.3333, 0.4000]])
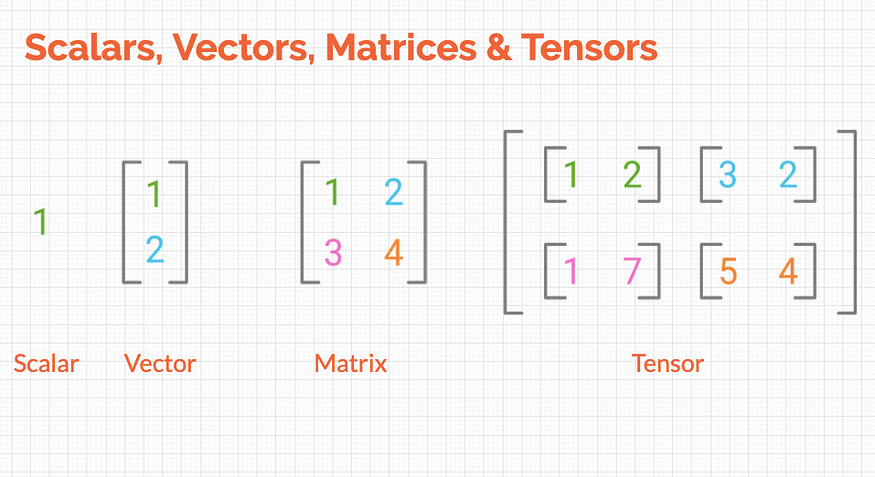
In [15]:
tensor1 = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
tensor1
Out[15]:
tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
In [16]:
tensor2 = torch.tensor([[[9, 10], [11, 12]], [[13, 14], [15, 16]]])
tensor2
Out[16]:
tensor([[[ 9, 10],
[11, 12]],
[[13, 14],
[15, 16]]])
In [17]:
# 두 텐서의 사칙 연산
print(tensor1 + tensor2)
print(tensor1 - tensor2)
print(tensor1 * tensor2)
print(tensor1 / tensor2)
tensor([[[10, 12],
[14, 16]],
[[18, 20],
[22, 24]]])
tensor([[[-8, -8],
[-8, -8]],
[[-8, -8],
[-8, -8]]])
tensor([[[ 9, 20],
[ 33, 48]],
[[ 65, 84],
[105, 128]]])
tensor([[[0.1111, 0.2000],
[0.2727, 0.3333]],
[[0.3846, 0.4286],
[0.4667, 0.5000]]])
In [18]:
print(torch.add(tensor1, tensor2))
print(torch.subtract(tensor1, tensor2))
print(torch.multiply(tensor1, tensor2))
print(torch.divide(tensor1, tensor2))
print(torch.matmul(tensor1, tensor2))
tensor([[[10, 12],
[14, 16]],
[[18, 20],
[22, 24]]])
tensor([[[-8, -8],
[-8, -8]],
[[-8, -8],
[-8, -8]]])
tensor([[[ 9, 20],
[ 33, 48]],
[[ 65, 84],
[105, 128]]])
tensor([[[0.1111, 0.2000],
[0.2727, 0.3333]],
[[0.3846, 0.4286],
[0.4667, 0.5000]]])
tensor([[[ 31, 34],
[ 71, 78]],
[[155, 166],
[211, 226]]])
In [19]:
print(tensor1.add_(tensor2)) # tensor1에 결과를 다시 저장
print(tensor1.subtract_(tensor2)) # 모든 사칙연산자에 _를 붙이면 inplace=True가 됨
tensor([[[10, 12],
[14, 16]],
[[18, 20],
[22, 24]]])
tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
In [20]:
tensor1
Out[20]:
tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
2. 텐서의 변환¶
In [21]:
data = [[1, 2], [3, 4]]
print(data)
[[1, 2], [3, 4]]
In [22]:
x_data = torch.tensor(data)
print(x_data)
tensor([[1, 2],
[3, 4]])
In [23]:
import numpy as np
In [24]:
np_array = np.array(x_data)
np_array
Out[24]:
array([[1, 2],
[3, 4]])
In [25]:
x_np_1 = torch.tensor(np_array)
x_np_1
Out[25]:
tensor([[1, 2],
[3, 4]])
In [26]:
x_np_1[0, 0] = 100
print(x_np_1)
print(np_array)
tensor([[100, 2],
[ 3, 4]])
[[1 2]
[3 4]]
In [27]:
# as_tensor(): ndarray와 동일한 메모리 주소를 가리키는 뷰를 만듦
x_np_2 = torch.as_tensor(np_array)
print(x_np_2)
x_np_2[0, 0] = 200
print(x_np_2)
print(np_array)
tensor([[1, 2],
[3, 4]])
tensor([[200, 2],
[ 3, 4]])
[[200 2]
[ 3 4]]
In [28]:
# from_numpy(): ndarray와 동일한 메모리 주소를 가리키는 뷰를 만듦
x_np_3 = torch.from_numpy(np_array)
print(x_np_3)
x_np_2[0, 0] = 400
print(x_np_3)
print(np_array)
tensor([[200, 2],
[ 3, 4]])
tensor([[400, 2],
[ 3, 4]])
[[400 2]
[ 3 4]]
3. 파이토치 주요 함수¶
In [29]:
a = torch.ones(2, 3)
print(a)
tensor([[1., 1., 1.],
[1., 1., 1.]])
In [30]:
b = torch.zeros(2, 3)
print(b)
tensor([[0., 0., 0.],
[0., 0., 0.]])
In [31]:
c = torch.full((2, 3), 10)
print(c)
tensor([[10, 10, 10],
[10, 10, 10]])
In [32]:
d = torch.empty(2, 3)
print(d)
tensor([[-1.2108e+00, 4.5162e-41, -1.2108e+00],
[ 4.5162e-41, 0.0000e+00, 0.0000e+00]])
In [33]:
e = torch.eye(5)
print(e)
tensor([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
In [34]:
g = torch.rand(2, 3)
print(g)
tensor([[0.2866, 0.0948, 0.7761],
[0.6424, 0.8792, 0.1796]])
In [35]:
h = torch.randn(2, 3) # 평균이 0이고 표준편차가 1인 정규분포에서 무작위 샘플링
print(h)
tensor([[ 0.0136, -0.8438, -0.8695],
[ 1.5340, -0.7038, 1.1265]])
In [36]:
i = torch.arange(16).reshape(2, 2, 4)
print(i, i.shape)
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]]) torch.Size([2, 2, 4])
In [37]:
# permute(): 차원을 지정한 인덱스로 변환
# i = (2, 2, 4)
j = i.permute((2, 0, 1)) # (2, 2, 4) -> (4, 2, 2)
print(j, j.shape)
tensor([[[ 0, 4],
[ 8, 12]],
[[ 1, 5],
[ 9, 13]],
[[ 2, 6],
[10, 14]],
[[ 3, 7],
[11, 15]]]) torch.Size([4, 2, 2])
4. 텐서의 인덱싱과 슬라이싱¶
In [38]:
a = torch.arange(1, 13).reshape(3, 4)
print(a)
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
In [39]:
print(a[1])
tensor([5, 6, 7, 8])
In [40]:
print(a[0, -1])
tensor(4)
In [41]:
print(a[1:-1])
tensor([[5, 6, 7, 8]])
In [42]:
print(a[:2, 2:])
tensor([[3, 4],
[7, 8]])
5. 코랩에서 GPU 사용하기¶
- 코랩에서 device 변경하는 방법
- 상단 메뉴 -> 런타임 -> 런타임 유형 변경-> 하드웨어 가속기를 GPU로 변경 -> 저장 -> 세션 다시 시작 및 모두 실행
In [43]:
tensor = torch.rand(3, 4)
print(f'shpae: {tensor.shape}')
print(f'type: {type(tensor)}')
print(f'dtype: {tensor.dtype}')
print(f'device: {tensor.device}')
shpae: torch.Size([3, 4]) type: <class 'torch.Tensor'> dtype: torch.float32 device: cpu
In [44]:
# is_available(): gpu를 사용할 수 있는지 여부
tensor = tensor.reshape(4, 3)
tensor = tensor.int()
print(f'shpae: {tensor.shape}')
print(f'type: {type(tensor)}')
print(f'dtype: {tensor.dtype}')
if torch.cuda.is_available():
print('GPU를 사용할 수 있음')
tensor = tensor.to('cuda')
print(f'device: {tensor.device}')
shpae: torch.Size([4, 3]) type: <class 'torch.Tensor'> dtype: torch.int32 GPU를 사용할 수 있음 device: cuda:0
In [44]:
'코딩 > 머신러닝과 딥러닝' 카테고리의 다른 글
| 파이토치로 구현한 논리회귀 (0) | 2024.07.17 |
|---|---|
| 파이토치로 구현한 선형회귀 (0) | 2024.07.17 |
| KMeans (0) | 2024.07.17 |
| 다양한 모델 적용 (0) | 2024.07.17 |
| LightGBM (0) | 2024.07.17 |